Precision - TP/ (TP+FP)
- Ability to reliably reject non-relevant documents
- Important if costly for non-relevant item to get mistakenly accepted (job applications)
Recall - TP/ (TP + FN)
- Ability to reliably find all relevant documents
- Important if costly for relevant items to get missed (safety-critical applications like self driving or medicine)
Harmonic Mean - for averages to be valid, need denominators to have the same scaled units
- F1 score - Reciprocal of the arithmetic mean of the reciprocals of set of observations
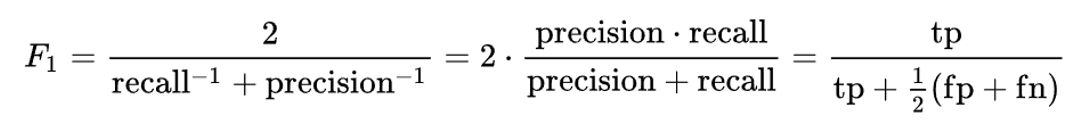 Precision-Recall (PR) Curve - plot precision against recall at all top-K values
Precision-Recall (PR) Curve - plot precision against recall at all top-K values - Average Precision (AP) - area under the PR curve
- mean Average Precision (mAP) - AP averaged across dataset
Shannon Information I(X=x) - intuitively is the level of “surprise” of a probabilistic realization
- The negative log of probability
- The higher the likelihood, the lower the shannon information
Shannon Entropy H(X) - expected value of shannon information
- If H(X) = 0, always same value so no information encoded in data
- H(X) = moderate, some underlying patterns that allow for information to be learned
- H(X) = high, many possibilities of values; need many bits to capture data
Cross Entropy H(P,Q) - intuitively, average number of total bits required to encode data coming from a “true” distribution P when we use model Q
- Cross entropy is minimum when P=Q
- Same as negative log-likelihood, just interpreted differently - also known as log loss
KL Divergence D(P||Q) - average number of EXTRA bits required to encode data from P when we use Q
- Characterizes how much more likely x is drawn from P vs Q
- Essentially, cross entropy H(P,Q) is KL Divergence of (P,Q) plus entropy of P
- If P is fixed, then minimizing cross entropy is the same as minimizing KL divergence
- KL has a forward and reverse interpretation
- Forward KL - mode-covering behavior
- Reverse KL - mode-seeking behavior
- Knowledge distillation - training a student to replicate behavior of a teacher - use KL divergence instead of cross entropy since entropy is non-zero
- Non-zero entropy means “optimal” loss is non-zero and constantly fluctuates depending on batch
MSE Loss (Mean squared error) - typically used for regression while cross entropy usually used for classification
- Possible to use MSE for classification but MSE + softmax is not convex
- MSE decomposes to the bias and variance
Bias - bias for a parameter estimator is the difference between expected value and underlying parameter
- Underfitting if bias is high Variance - how consistent given different training datasets
- Overfitting if variance is high
Double descent phenomenon - phenomenon challenges bias-variance tradeoff
- Overly complex model that overfits might perform better than well parameterized models
- Theory: allows model to find simpler solution that generalizes better, or is better able to fit and distinguish noise from signal
Curse of dimensionality - the larger the dimension, the more sparse the data space given a certain amount of data
- Data becomes equally spaced which is bad
- Amount of data to support high dimensionality grows exponentially
 Blessing of Dimensionality - advantage to working with high dimensionality
Blessing of Dimensionality - advantage to working with high dimensionality - high dimension can make points separable when a lower dimension cannot
Discriminative vs Generative Models
- Discriminative models probability of Y given X, P(Y|X) - given feature X, what is the probability of it being in one class or the other?
- Generative model learns distribution of individual classes - learns PDF of X for all classes of Y